
AI Trust Drops as Adoption Accelerates: Key Findings
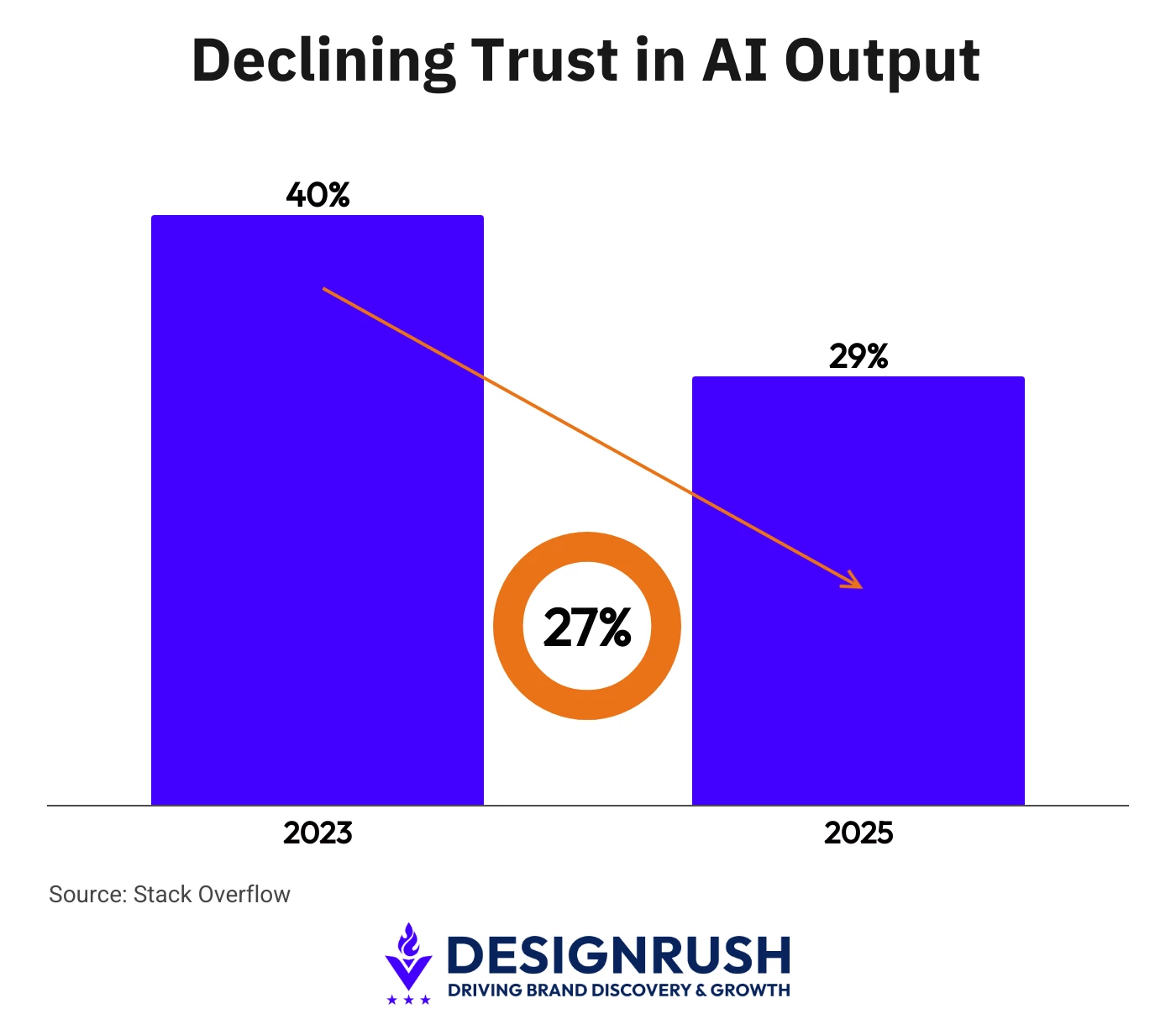
- AI trust dropped from around 40% in 2023 to just 29%, representing a 27.5% relative decline.
- 37% of the time employees saved using AI tools was lost to correcting mistakes in AI-generated output.
- Unico Connect treats AI evaluations as a continuous discipline, embedding evals into workflows like CI/CD to catch regressions before they reach users.
Only 29% of developers say they trust AI-generated output in 2025, down from around 40% in 2023, according to Stack Overflow’s 2025 Developer Survey.
That represents a 27.5% relative decline in trust over two years.
A separate Stack Overflow survey found that 20.7% of experienced developers highly distrust the accuracy of AI outputs.
Given a majority of companies now use AI in at least one business function, this lack of confidence is concerning.
This is not a story about developers rejecting AI. After all, they are using AI more, not less.
This is about a growing gap between adoption and confidence.
As CEO of Unico Connect, an AI-native software development company, I’ve seen companies face a whole host of issues when adopting AI.
From unreliable outputs to teams constantly rechecking “almost right” results, these obstacles slow down teams and pose real operational risks.
And that’s why it’s imperative to fix them.
The Trust Problem Is a Quality Problem
According to the Stack Overflow survey, 66% of developers said they regularly deal with AI-generated solutions that are “almost right, but not quite.”
Forty-five percent reported that debugging AI-generated code is more time-consuming than debugging code they wrote themselves.
A separate report from Workday found that 37% of the time employees saved using AI tools was lost to correcting, clarifying, or rewriting low-quality AI-generated content.
For organizations deploying AI in customer-facing products, the stakes are higher.
An AI feature that works correctly 90% of the time sounds impressive in a demo.
But in production, that 10% failure rate translates to support tickets, user frustration, and in regulated industries, potential compliance issues.
The question is not whether AI output needs to be checked. It’s how you build a systematic process for checking it.
What AI Evaluations Actually Are
AI evaluation, which we’ll now refer to as “evals,” is the discipline of measuring whether AI outputs meet defined quality standards.
If you come from a software engineering background, the closest analogy is test suites.
While traditional tests check whether code executes correctly against known inputs and expected outputs, AI evals assess qualities that are harder to pin down, including:
- Accuracy
- Relevance
- Consistency
- Safety
- Contextual appropriateness
An eval framework typically includes a set of reference scenarios (inputs the AI is expected to handle), defined criteria for what constitutes an acceptable response, and automated scoring that runs continuously as the AI system is updated.
Some evals are quantitative, measuring factual accuracy against a known dataset.
Others are qualitative, assessing whether the tone, format, or reasoning of a response meets the standard a human reviewer would accept.
This discipline isn’t new. Research labs and large AI companies have used evaluations internally for years.
What is new is the need for product teams and engineering organizations to build eval frameworks into their own development processes, not as a one-time audit, but as a continuous practice.
Why Evals Need to Be Continuous, Not Occasional
One of the most common mistakes organizations make is treating AI evaluation as a milestone activity or something that happens before launch and occasionally after major updates.
This approach misses the nature of how AI systems behave in production. To be more specific, it overlooks the fact that AI models change.
Providers update models, fine-tune data shifts, and prompt configurations evolve.
A system that scored well on evals in January may perform differently by March, not because anyone made a deliberate change, but because the underlying model was updated.
Without continuous evaluation, these regressions go undetected until users report them.
Production data also drifts as the amount of data collected and interpreted increases.
The inputs your AI handled in month one are not the same as the inputs it handles in month six. Likewise, users will find edge cases, new patterns will emerge, and the distribution of requests will shift.
An eval framework that runs on the same reference set from launch day will miss these shifts entirely.
At Unico Connect, we treat AI evals the way most teams treat CI/CD pipelines. This means they run on every change, not just before release.
So if your evaluation process is static, you are flying blind.
Every team shipping AI features needs an eval framework that runs continuously, catches regressions before users do, and gives the team confidence that what they shipped last week still works today.
Building an Eval Practice
The starting point does not need to be complex. Teams that are new to evals can begin with three elements.
First, define what “good” looks like for your specific use case. This is harder than it sounds – it requires product and engineering teams to agree on measurable quality criteria, not just subjective impressions.
Second, build a reference set of test scenarios that represents the range of inputs your AI handles, including edge cases and adversarial inputs.
Third, automate the scoring so it runs without manual intervention. Manual review has a role, but it does not scale.
From there, the framework evolves.
You add evals for new failure modes as they surface. You incorporate production data into your reference sets. You build dashboards that show eval scores over time, so regressions are visible before they reach users.
The Business Case for Eval Rigor
Developers do not distrust AI because the technology is fundamentally flawed.
They distrust it because they have seen it produce output that looks correct but is not, and they have experienced the cost of finding out too late.
For organizations, the practical response is not to slow down AI adoption. It is to build the evaluation discipline that makes adoption sustainable.
The companies that invest in structured, continuous AI evaluation will ship with more confidence and catch failures earlier.
They’ll also build the kind of reliability that turns AI features from experiments into competitive advantages.





