
Data Security in AI Systems: Key Findings
- Data management and security have become central priorities as AI adoption accelerates.
- AI introduces new risks across the entire data lifecycle, including unclear data residency, weak control over inputs, and vulnerabilities across multi-vendor supply chains.
- Security must be embedded across the AI lifecycle from day one, with governance, encryption, and infrastructure controls ensuring safe and compliant AI adoption.
Businesses in the majority of industries are under immense pressure to implement AI to stay competitive.
But despite rapid adoption, many leaders still have doubts.
Salesforce’s State of IT report revealed that only half of IT leaders expressed full confidence that their data infrastructure can yield AI success.
As a result, data management and security have become central priorities for enterprise leaders, with data security and privacy ranking as the top concern for CIOs.
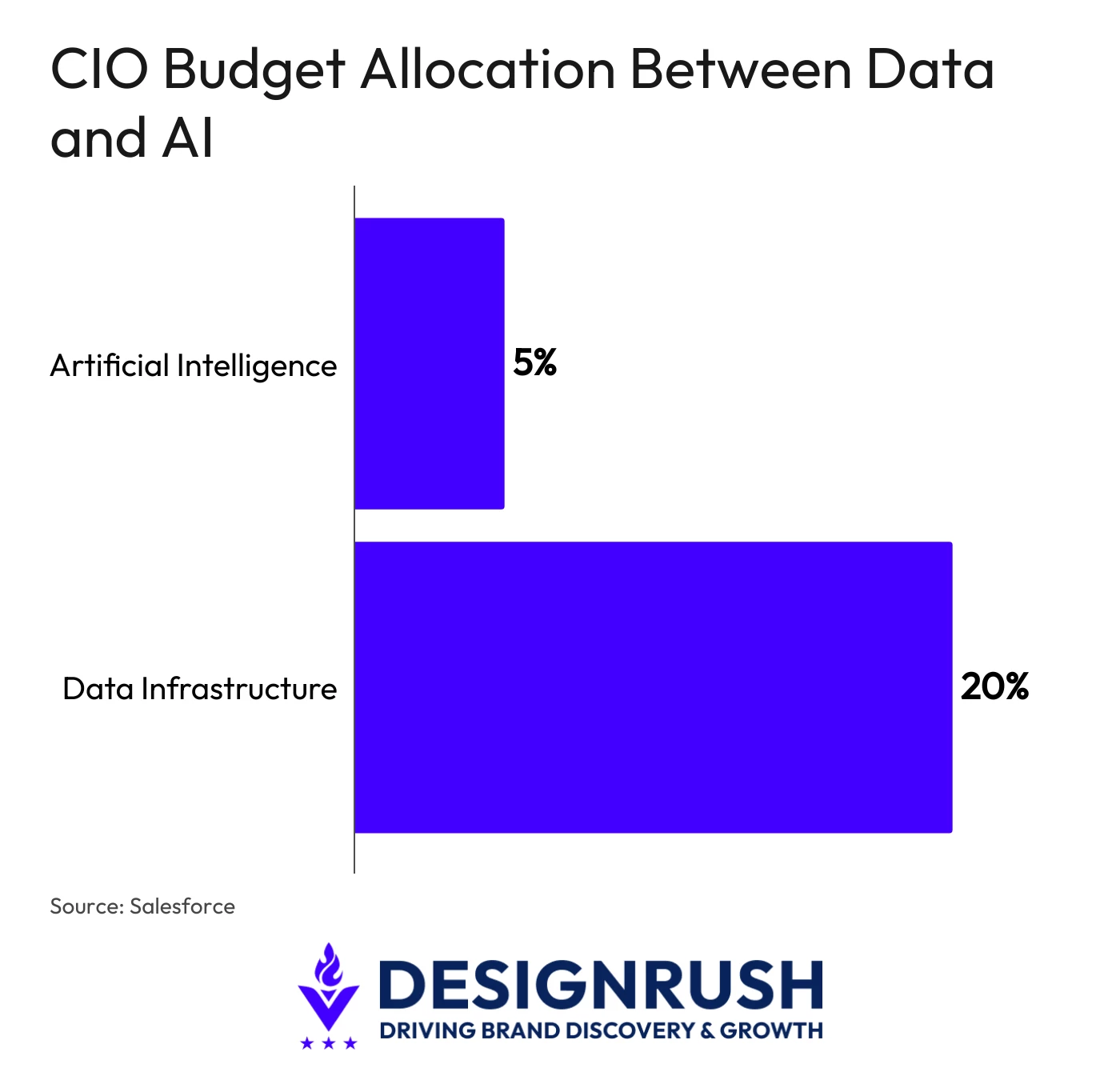
In light of this, CIOs allocate, on average, four times more budget to data infrastructure than to AI, according to Salesforce research.
But with the technology now becoming the backbone of many companies’ operations, the old ways of handling security don’t work.
After all, AI can learn, transform, and share data across your infrastructure, and even hand it to third parties.
This exposes organizations in never-before-seen ways that urge them to adapt existing security frameworks.
The Key Challenges of AI in Data Security
No one can deny that for AI to work at its best, it needs good, clean data. And lots of it.
Despite this, CIOs surveyed by Salesforce say that data security threats remain as one of their top challenges.
To be more specific, leaders are particularly concerned about the following:
Lack of Control Over Input Data and Access
Today, when an organization subscribes to a reputable AI-based SaaS service to help employees optimize reasoning in their day-to-day activities, it also gives away access to data that it won’t ever allow in any other vendor relationship.
The problem is that even when a vendor states that your corporate data won’t be used for model training, there is no reliable way of verifying it.
Moreover, all the data the employees share with the system goes through a web of servers and APIs, which is something an organization will never have access to.
Essentially, lack of control over inputs is one of the most important risks of enterprise AI adoption.
Unclear Data Residency
The regulatory enforcement regarding data privacy becomes stricter by the day.
However, most AI platforms offer little to no insight into where data storing and processing is happening.
Unless you specifically negotiate regional hosting or deploy models locally, your data may sit in a jurisdiction that conflicts with your legal obligations.
Enterprises bound by frameworks like GDPR and HIPAA have to be especially careful, as minor compliance issues quickly turn into huge regulatory fines.
Data Anonymization is Not Enough
Anonymization, a tried and tested way of addressing privacy concerns, is no longer as efficient as it once seemed to be.
Modern AI tools can identify individuals from anonymized datasets by correlating behavioral patterns.
Regulators were quick to address this. Today’s standards for anonymization in regulatory frameworks like GDPR are so high that few enterprises can handle them.
Poor Data Quality
While many organizations now put significant effort into enhancing how they collect, store, and analyze data, they have no control over the data sources used for model training by third-party AI vendors.
Models trained on data of poor quality will inevitably produce misleading and biased decisions.
However, it’s the organization that will take the responsibility and bear the regulatory consequences.
Lack of Security Across the AI Supply Chain
Most AI tools are interdependent systems composed of many elements that work together rather than a single tool.
Hardware, data pipelines, API integrations, and many other endpoints all form a chain, and a breach in any of those components has a butterfly effect on the whole system.
Be it compromised training data or a vulnerable API, security has to extend to every component in the chain.
5 AI Security Best Practices
The following five practices comprise an actionable framework for closing critical security gaps, from how data enters the system to how it produces its final output.
1. Build Vulnerability Management into the AI Lifecycle
Regardless of the industry, every AI system has three attack points: its inputs, the model itself, and its outputs.
Organizations have to treat each with a distinct security approach. Here’s how:
- Validate inputs and enforce access controls to minimize exposure to vulnerabilities at the entry point.
- Apply threat modeling and inspect third-party libraries to bolster model security.
- Monitor and filter outputs to ensure the model can’t include hidden code or sensitive data.
2. Establish Data Governance before Deployment
Way before the AI system deploys, you need to know where exactly the data will be stored and processed.
This implies conducting Privacy Impact Assessments for use cases with regulated data, validating alignment with frameworks like GDPR, and ensuring that a legal base for data processing is in place.
User consent is non-negotiable when dealing with sensitive data.
3. Secure the Infrastructure with Automation
In most cases, manual security processes suit only small and stable AI environments.
For complex multi-vendor AI ecosystems, it’s best to apply the MLOps approach.
By utilizing DevOps principles in an AI context, enterprises can enforce consistent access controls and build security checkpoints into CI/CD pipelines.
This results in secure model storage, encrypted data transfers between environments, and uniform API security management
4. Protect Data End-to-End
When it comes to AI systems, data moves through countless layers, including pre-processing pipelines, training environments, compliance checkers, etc.
This exponentially increases the range of attacks the data is vulnerable to and makes end-to-end encryption a necessity.
Data has to be guarded at every stage of the data lifecycle.
This involves applying tokenization, maintaining documented data provenance so the origin and handling history can be verified, and applying data loss prevention techniques.
And never feed sensitive data into commercial pre-trained models unless there are explicit contractual protections.
5. Making Security a Part of the Foundation
AI sits at the foundation of today’s enterprise tech stack, making its security implications hard to ignore.
The security risks outlined above become more prevalent as the technology matures, and being proactive in security management becomes a prerequisite for robust, long-lasting AI-driven enterprises.
With the right combination of governance, infrastructure control, and data protection practices, organizations can reap the benefits of AI while being on top of the evolving security threats.
It’s paramount to treat security as part of the foundational design that is embedded into every layer of AI from day one





