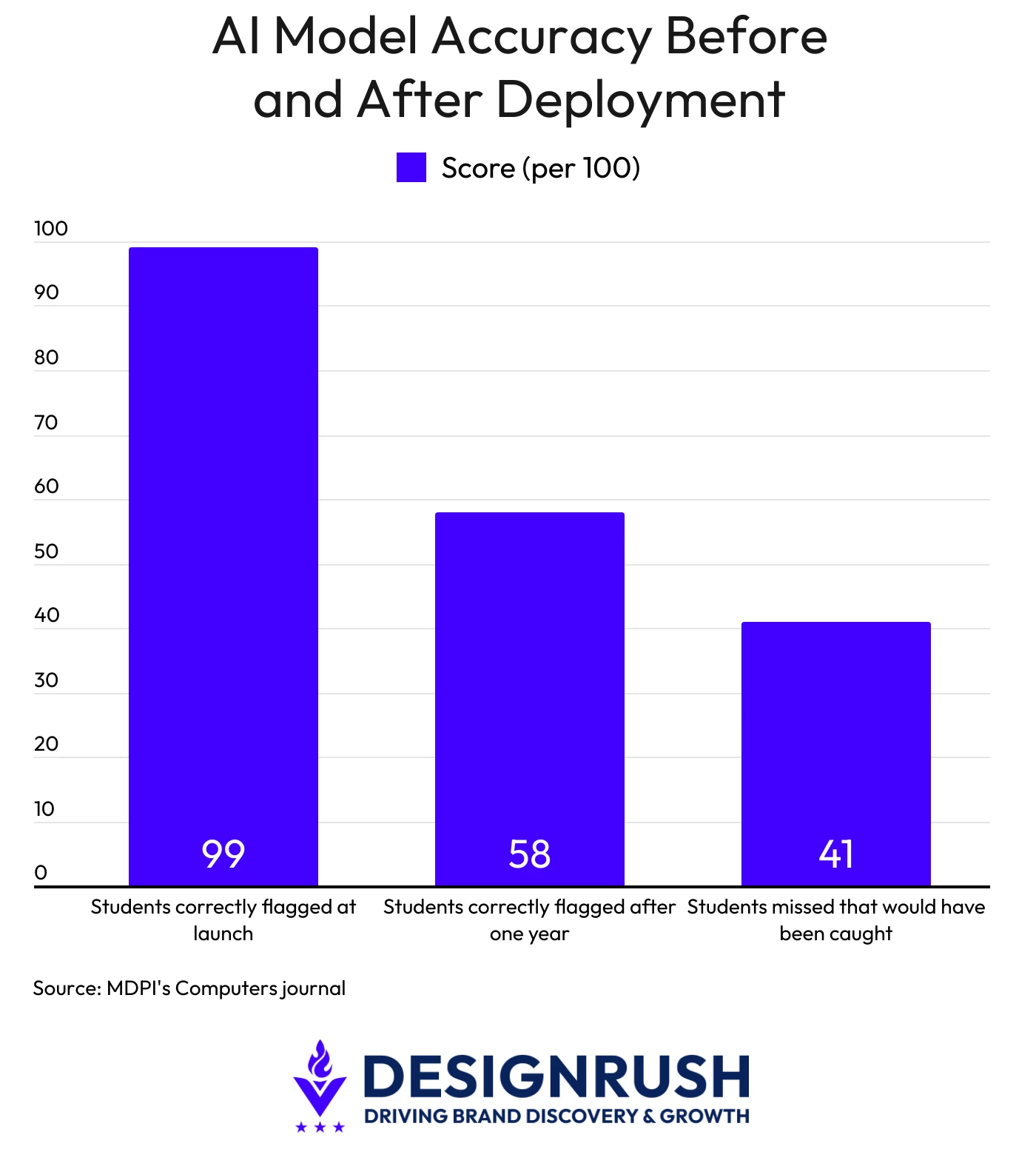
A machine learning model that originally identified nearly every at-risk student saw its recall drop from 0.99 to 0.58 after deployment as the input data changed.
The drop was documented in a 2025 peer-reviewed study published in MDPI's Computers journal. The model tracked students across multiple academic years.
In practical terms, at 0.99, the system caught 99 out of every 100 students who needed intervention, while at 0.58, it missed more than four out of ten.
A fraud detection model faces the same exposure when attack patterns evolve. So does a churn model when customer behavior shifts, or a demand forecast when market conditions change.
And that vulnerability has the same root cause across all of them.
Machine learning models are built on a fixed snapshot of historical data. When the patterns in that data shift, the model's accuracy shifts with them.
Model degradation is a recurring challenge across industries, according to a review of over 60 peer-reviewed drift detection methods.
The authors of the review call this concept drift, the gradual shift in the statistical patterns a model was trained on.
Degradation normally occurs slowly enough to avoid quick attention, which is what makes it expensive.
Tracking Infrastructure While Models Drift
A number of organizations already track infrastructure health. They monitor server uptime, cloud spending, API latency, and system availability.
Fewer apply the same discipline to model behavior.
A system can remain fully operational while its predictions become increasingly inaccurate.
The underlying degradation may have been developing for months by the time a business statistic starts to decline.
But why do so many teams miss this until it's too late?
Unico Connect, an AI-native software development firm, designs monitoring into rollouts from the start precisely because that question goes unasked.
"Many organizations focus heavily on model development and deployment, but far fewer invest in understanding how those models behave months later in production," says Malay Parekh, CEO of Unico Connect.
Unlike infrastructure failures, model degradation produces no error message. The system keeps running while the predictions quietly lose their footing.
Drift Is an MLOps Problem
MLOps refers to the operational practices that keep production AI systems running reliably over time. Most teams invest in it at launch. Few extend it to cover what happens after.
The MDPI study found that behavioral inputs, data reflecting live user activity, drifted furthest from what the model was trained on.
Static profile data held steady, but the model could not distinguish between them.
When that gap grows large enough, a model running at 0.58 recall generates decisions based on patterns that no longer reflect reality.
The organizations acting on those outputs often have no way of knowing the model has degraded. That finding points to a structural problem.
The researchers tested whether adjusting model settings and removing the most unstable features would help.
The improvements were real but modest. Architectural fixes alone cannot compensate for a monitoring infrastructure that does not exist.
"Behavioral features drift precisely because they reflect live user activity. Removing them would stabilize the model at the cost of its predictive power," Parekh notes.
"That is not a reason to avoid them. It is a reason to build monitoring around them from day one."
Unico Connect's approach to AI production includes input distribution monitoring as a production requirement rather than an optional addition after launch.
Monitoring Catches Drift Before the Business Does
Retraining models on a fixed schedule is the most common response to declining performance.
It can help, but it assumes teams already know performance has deteriorated and understand what changed.
Without drift detection, those assumptions are difficult to validate. Teams may retrain too soon, too late, or on data that misses the actual source of drift.
As AI adoption grows, organizations are beginning to view monitoring as an essential component of the AI deployment lifecycle.
The objective is to catch shifts in input data and model accuracy before they reach revenue, retention, or compliance metrics.
"Organizations that build monitoring into the product from the start spend less time firefighting and more time improving," Parekh says.
"Visibility into model health allows teams to act before performance issues become expensive problems."
Deployed Models Have an Expiration Date
Most post-deployment audits focus on bias, security, and system availability.
Gradual loss of accuracy from shifting data patterns rarely gets the same attention, despite being the most predictable failure mode in any long-running deployment.
The MDPI study reveals a detail worth examining closely. The features that drifted most were the behavioral ones, the inputs that reflect how people interact with a system over time.
These are also the features that make models valuable in the first place. A model built only on static data is stable but limited.
On the other hand, a model that incorporates live behavioral signals is powerful, yet requires active maintenance.
That is the trade-off most teams never acknowledge. Behavioral data makes predictions better. It also makes models more fragile over time.
Monitoring is what closes that gap. Teams that skip it are running outdated snapshots and calling them AI.





