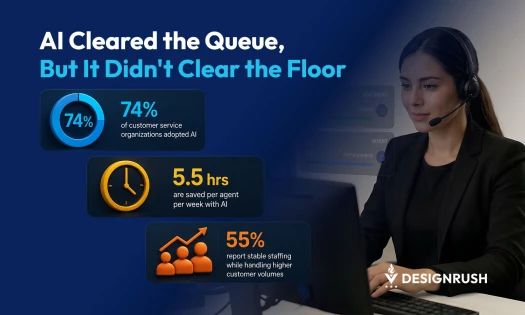
AI errors already cost businesses $67.4 billion globally in 2024, per industry research.
Thirty percent of organizations report AI inaccuracy consequences, 11% privacy violations, and 8% IP infringement, according to McKinsey's 2025 Global Survey on AI.
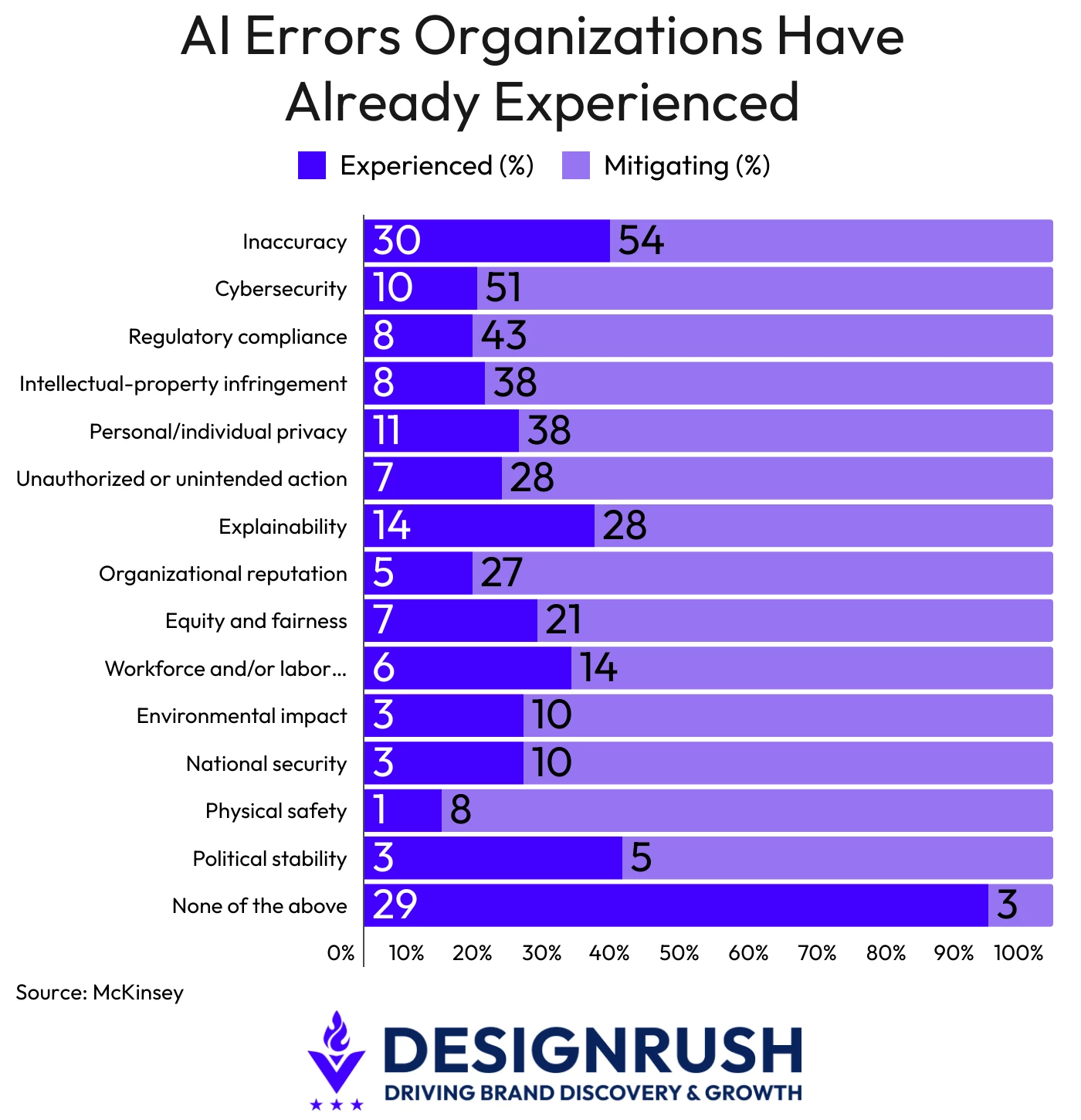
Of those, inaccuracy is the most common, and one of its least audited sources is fine-tuning on personal data.
When a company adapts a model on internal records, they do not stay separate. The model learns from them, and the patterns can resurface in its outputs.
Fine-tuning on personal data can raise how much a model reproduces that data by as much as 7.5 times, according to researchers at Northeastern University and Google DeepMind.
Privacy exposure rates rise from near zero to between 60% and 75% when sensitive data appears repeatedly during training.
That finding comes from a separate study on large language model memorization.
Both findings come from controlled experiments. Most model adaptation projects run no equivalent tests before deployment.
The Data Stays Encoded Long After Training
Most organizations assume the exposure is contained once training ends. The Northeastern study documents something more difficult to manage.
The researchers call it assisted memorization. Personal data that showed no signs of exposure immediately after fine-tuning became reproducible later.
Subsequent training on related data activated patterns that were dormant at launch.
This means an organization can pass its own internal audit and still carry exposure that compounds with every model update.
Unico Connect, an AI-native software development firm, treats this as a governance exposure that most model training projects never surface before launch.
"Most teams ship a model when the accuracy metrics look right. Nobody runs a test to see what the model will say if someone asks it the right question about a customer it trained on," says Malay Parekh, CEO of Unico Connect.
View this post on Instagram
Every subsequent training cycle on a model that already learned from sensitive data can expand what the model can reproduce, not only preserve it.
Fine-Tuning Creates Three Governance Exposures
The governance risk falls into three categories that rarely appear in standard pre-deployment checklists.
PII the Model Can Now Reproduce
Customer records, employee data, and support transcripts, all personally identifiable information (PII), used in fine-tuning can reappear in model outputs.
Exposure rates rise from near zero to over 60% when sensitive data appears repeatedly during training. Most teams discover this after deployment, not before.

"We have seen organizations pass internal audits at launch and then watch personal data surface in outputs after a routine model update triggered patterns that were dormant from day one," Parekh says.
Applying data masking before training reduces the risk but does not eliminate it when masking covers only part of the dataset.
A model that answers a query accurately may draw on customer data the organization never intended to make accessible.
IP Rights That Don't Cover Training Use
Internal documents, third-party research, and licensed content fed into model training may carry legal restrictions that do not extend to training use.
Many organizations assume that data they own or license is available for any internal purpose. Training use is often a separate right that requires explicit clearance.
Using this data without confirming those rights creates intellectual property exposure that persists inside the model.
That exposure travels with every output the model generates, regardless of how the outputs are later used or distributed.
Data That Survives Retraining
The Northeastern study found that removing personal data from a fine-tuning dataset and retraining does not produce a clean model.
Removing one layer of retained data exposed the next most likely layer beneath it. The researchers call this the onion effect.
For compliance teams, this means one round of remediation rarely resolves the full scope of what the model retained.
Each attempt to clean the model can surface new exposure rather than closing the issue.
Retraining Shifts the Exposure
Many organizations respond to data exposure concerns by retraining on cleaner datasets, assuming this resets the risk. The memorization research found otherwise.
Even randomly removing data from a training set, not just the identified sensitive material, triggered new retention of previously dormant content.
The exposure moved to different data rather than resolving.
That problem compounds when organizations lack data lineage, a documented record of where training data originated, how it was transformed, and which pipelines it passed through.
Without it, organizations cannot identify which customer records entered the model, under what rights, or at what point in the training process.
Unico Connect runs extraction tests as part of every model training engagement, mapping what the model can reproduce before it reaches production.
"Some clients have no monitoring in place after launch. The model runs, the outputs look fine, and the exposure accumulates silently until a regulatory inquiry forces the audit that should have happened first," Parekh adds.
View this post on Instagram
Combining deduplication, controlled noise during training, and output filtering can reduce exposure to near zero.
The memorization study found this approach maintained 94.7 percent of the original model performance while eliminating leakage.
Some performance reduction is inherent to the protection.
Fine-Tuning Is a Legal Surface
Most organizations audit what their team added to fine-tuning. The foundation model's prior training and whatever it already encoded rarely comes under the same scrutiny.
The Stanford Foundation Model Transparency Index 2025 scored major AI companies on how openly they disclose information about their models.
Data acquisition and data properties ranked among the lowest areas, with companies averaging 40 out of 100 overall.
That opacity means organizations fine-tuning on top of these models are building on a foundation whose data history is not fully known.
Privacy regulations, intellectual property rights, and data processing agreements apply to the full model.
A defense based on the top layer alone rarely holds when the underlying model's training data was never disclosed.
Before fine-tuning, organizations should document what the base model trained on, confirm what data rights cover training use, and define what extraction tests will verify the outputs.