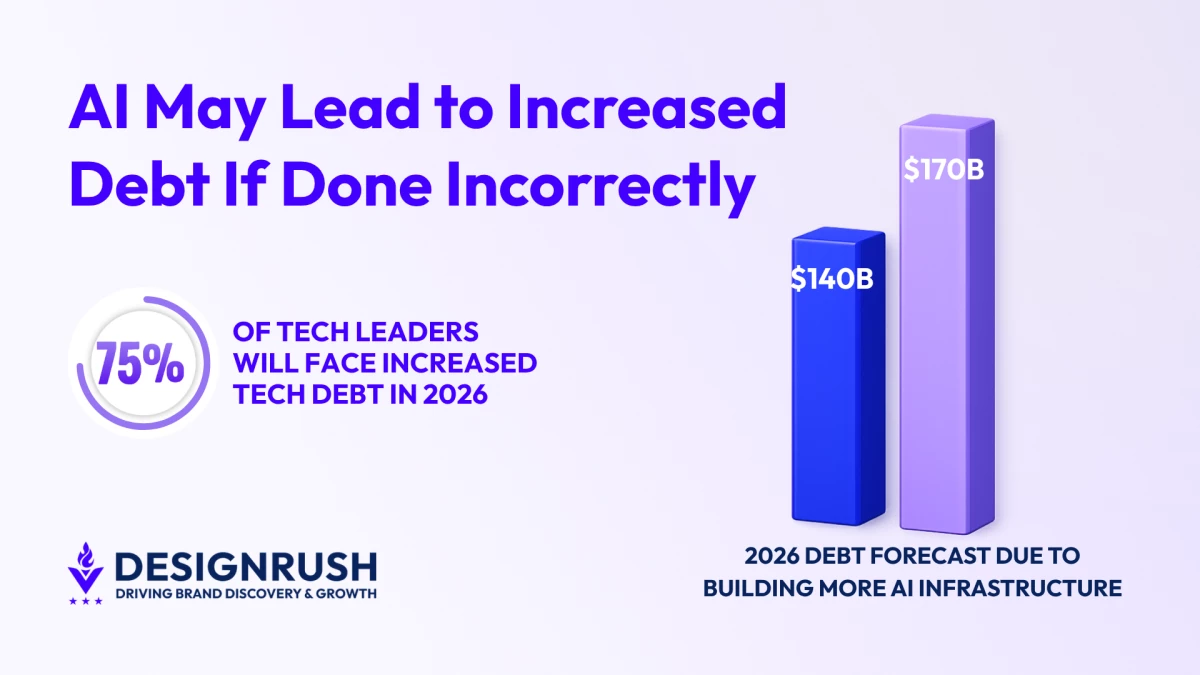
Analysts at BofA Global Research raised their 2026 hyperscaler debt forecast to $175 billion, up from $140 billion.
The revision followed Amazon's $54 billion bond sale, which drew nearly four times the demand for the total amount sold.
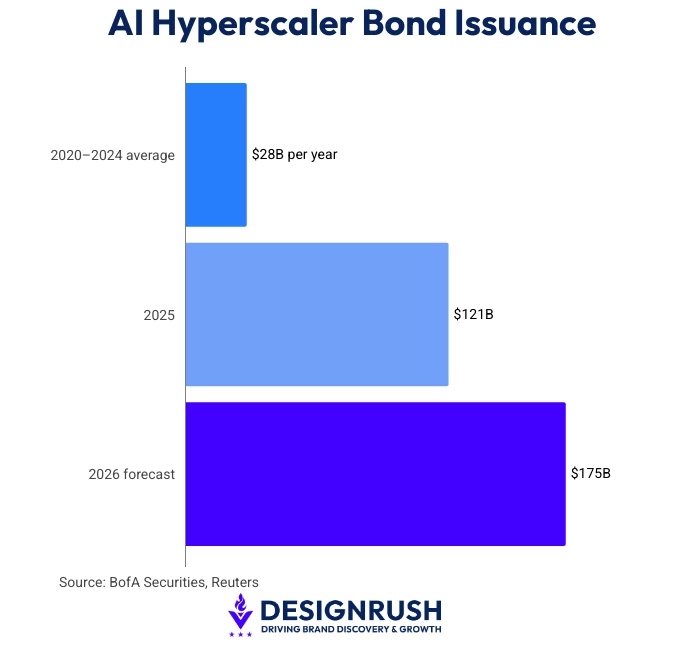
The five major AI hyperscalers, Amazon, Alphabet's Google, Meta, Microsoft, and Oracle, issued $121 billion in U.S. corporate bonds in 2025.
That compares to an average of $28 billion per year between 2020 and 2024.
 AI infrastructure costs money because systems built to scale cost money to build. For most web applications, that pressure is arriving without the budget to match it.
AI infrastructure costs money because systems built to scale cost money to build. For most web applications, that pressure is arriving without the budget to match it.
What $175B in AI Debt Reveals About Scalability
Hyperscalers are borrowing because running systems at AI-driven load demands infrastructure built specifically for that purpose.
Amazon raised $37 billion across 11 tranches in March alone. Alphabet issued $31.51 billion in February, including a rare 100-year bond. These are long-term architectural bets.
View this post on Instagram
AI-driven traffic and data volume are increasing across the web, not just inside hyperscaler environments. Systems that were adequate two years ago are already showing strain.
Quixta founder Anand Ashok noted that what hyperscalers are spending on web application infrastructure tells you exactly how much it costs to build systems that scale.
“Teams optimize based on assumptions rather than real usage data, which creates technically impressive but unnecessary solutions that add cost and complexity, divert effort from features users actually need, and slow down delivery," he adds.
Speed to Market Creates a Scalability Debt
According to McKinsey, companies paying down technical debt instead of building new offerings are caught in a spiral that gradually compounds.
In fact, tech debt costs $2.41 trillion a year and would require $1.52 trillion to fix in the U.S. alone, according to Accenture.
That pattern surfaces in smaller systems as latency, debugging hours, and emergency rework.
The further a system drifts from its original design assumptions, the more expensive every change becomes.
Architecture Decisions That Determine Scale
The choices that determine whether a web application can handle growth are made before the first user arrives.
Database schema design, module structure, API call patterns, and third-party dependency management all shape how a system behaves under pressure.
| Common Failure Pattern | Scalable Approach |
| Schema designed for current data volume | Schema built for projected growth |
| Sequential API calls | Parallel API calls |
| Monolithic architecture | Modular architecture |
| Third-party dependencies for core functions | Owned infrastructure for critical systems |
| Performance optimization post-launch | Performance built into initial architecture |
The most common failure patterns follow a consistent sequence:
- Schemas designed for today's data volume rarely accommodate growth without significant rework.
- Sequential API calls that work at low traffic create bottlenecks at scale.
- Third-party dependencies introduce rate limits and pricing variability that later constrain the system.
"Development teams make the architecture decisions that determine whether a system scales in the first weeks of a project. Everything after that is damage control," says Ashok.
Performance Optimization Is an Architecture Decision
Performance is treated as a post-launch concern in most early-stage builds. By that point, fixing bottlenecks requires significant re-architecture effort.
Retrofitting a caching layer or reworking data-fetching logic is significantly more expensive than building it into the system from the start.
Software design inefficiencies account for 42% of performance problems in large-scale backend systems, according to Wjarr research, which analyzed over 200 REST API endpoints.
That’s because excessive data processing within request handlers leads to CPU utilization spikes 2.3 times higher than baseline and latency increases of 160 to 350 milliseconds per request.
What AI-Driven Demand Requires From Development Teams
AI systems generate more requests, process larger datasets, and operate under tighter latency constraints than most web applications were designed to handle.
Quixta approaches this problem through early-stage planning that treats scalability as a product decision rather than a development phase. That means:
- Modular architecture over monoliths
- Forward-looking database schemas
- Performance optimization built into the initial build
Why?
Because the architectural baseline has moved, and teams that don't account for that in early planning are building systems that will require costly intervention later.
"Balancing scalability, performance, and cost requires treating cost as a first-class engineering concern from day one, not a post-deployment finance problem," says Ashok.
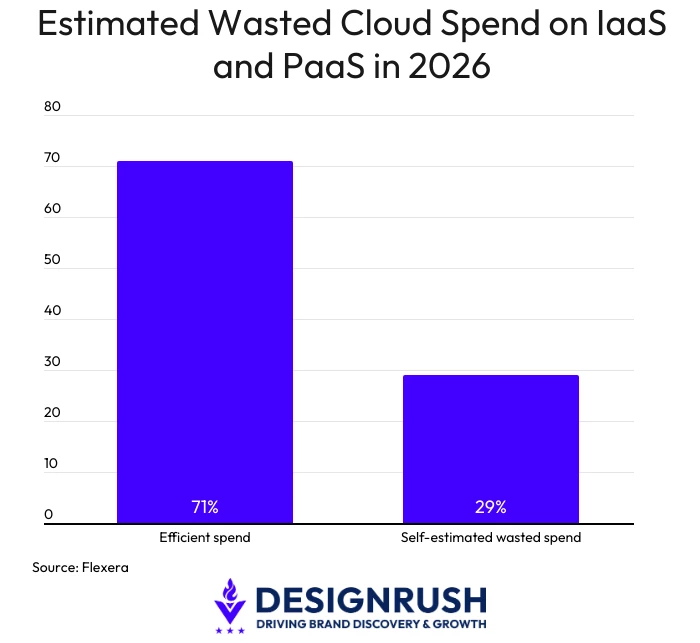
Case in point, organizations now waste 29% of their cloud spend on IaaS and PaaS to fix these issues, up for the first time in five years, per Flexera's 2026 State of the Cloud Report.
The Cost of Getting This Wrong
If Amazon needs $37 billion to build infrastructure that scales, that number is telling you something.
Scalable systems are expensive because the decisions that make them scalable are hard, and getting them wrong accumulates interest.
AI tools can generate a working prototype in hours. That prototype will handle your first hundred users. What happens at ten thousand is an architecture question, and it has a price.
McKinsey research shows that companies caught in a tech debt spiral spend more than half their IT project budget keeping existing systems functional.
That is the cost of speed without architecture. It arrives exactly when a product starts working, when losing users to downtime and latency is no longer a development problem but a revenue one.
