Web Data Takeaways:
- AI models perform best when trained on carefully selected, high-quality web data that directly supports a clear, focused use case.
- Finding consistent, up-to-date web sources is crucial, but overcoming anti-bot measures and messy site structures requires reliable tools and infrastructure.
- Turning raw web data into AI-ready insights involves cleaning, normalizing, automating updates, and delivering data in formats that fit seamlessly into AI workflows.
Effective AI depends on high-quality data, and the public web is now one of the most important sources for real-time, structured input.
Yet 71% of business leaders say they struggle to access the data they need to run their AI models effectively, according to market research partner Vanson Bourne.

Editor's Note: This is a sponsored article created in partnership with Bright Data.
From product reviews and job listings to real estate trends and market chatter, web data gives AI builders access to real-time signals that reflect the world as it is, not just as it was.
But transforming raw web data into something useful for machine learning is harder than it looks.
HTML is messy. Sites are inconsistent. Structures shift. And at scale, even small inefficiencies can break pipelines or bias outcomes.
Turning raw web data into AI-ready insights isn’t easy, but it’s an essential step in creating smarter AI.
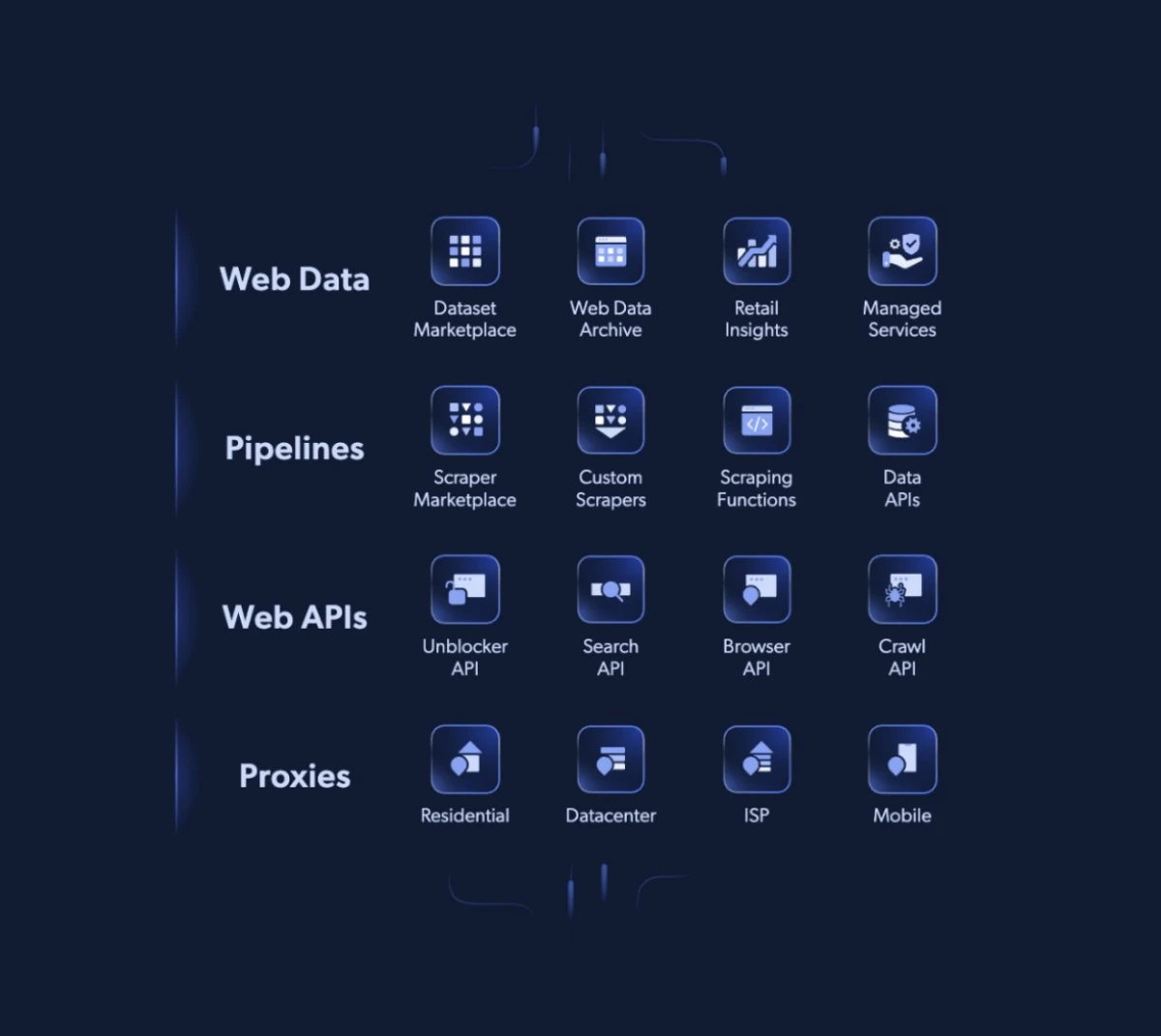
Web scraping platforms, like Bright Data, make this process easier by offering the tools and infrastructure that simplify web data collection and preparation.
Their tools and infrastructure help turn scattered, messy information into clean, structured data you can actually use.
Of course, simply having a web scraping platform isn’t enough. You also have to train your team on how to use and implement it correctly to get the most out of your chosen platform.
Understanding these steps gives you a clearer picture of what it takes to transform scattered web information into valuable data your AI can actually learn from.
1. Start With a Focused Use Case
Gathering data without a clear goal can quickly become overwhelming and inefficient.
The most effective data pipelines begin by answering key questions like:
- What is the AI model aiming to learn or predict?
- Which data attributes are absolutely essential?
- How frequently does the data need to be refreshed?
 For instance, if you’re building a retail price prediction model, you’ll want to focus on product titles, prices, discounts, and timestamps. On the other hand, less critical details like every product description or customer review may be less relevant.
For instance, if you’re building a retail price prediction model, you’ll want to focus on product titles, prices, discounts, and timestamps. On the other hand, less critical details like every product description or customer review may be less relevant.
“One of the clearest examples of the value of a focused use case is PowerDrop. Their platform helps eBay sellers identify top-selling products with good profit margins — so they knew exactly which signals they needed: pricing trends, top-performing merchants, and keyword popularity across 11 online marketplaces,” says Bright Data.
“That focus allowed them to avoid wasting resources on irrelevant data. Our proxy infrastructure, they were able to streamline collection, scale effectively, and deliver precise market research insights to their users.”
2. Identify Consistent, High-Signal Sources
With your use case clear, the next step is finding the right data sources. Focus on public websites that:
- Offer structured or semi-structured content like listings, forums, or catalogs
- Update their content regularly
- Follow patterns that can be programmatically extracted
“A top source for high-quality web data consistently publishes content in clear, predictable formats like product listings or job boards,” says x.
“They use structured markup and update regularly, keeping data fresh without overwhelming your system. Avoid sites with frequent layout changes or noisy, unstructured content—clean, stable data beats volume every time.”
Simply put, quality beats quantity here. It’s far better to gather 100,000 clean records from a handful of reliable sources than millions of messy, inconsistent ones from hundreds.
3. Solve for Access, Not Just Extraction
Collecting public web data at scale isn’t just about scraping HTML.
Many sites have anti-bot measures such as CAPTCHAs, IP throttling, geo-restrictions, and dynamic JavaScript that block or slow down automated data collection.
“The hardest barriers are dynamic defenses like rotating CAPTCHAs and session-based IP throttling that block scraping in real time,” says Bright Data.
“Leading platforms overcome these by mimicking user behavior with headless browsers and rotating compliant proxies.
Importantly, they also ensure full compliance with site policies and data regulations for safe, reliable access.”
 To work around these, data teams use tools like:
To work around these, data teams use tools like:
- Rotating proxies
- CAPTCHA-solving services
- Browser emulation
- Request header management
While these methods can be implemented manually, they quickly become complex at scale. This is especially true when dealing with multiple sources, evolving site structures, and the need for real-time updates across thousands of pages.
That’s why many teams turn to platforms that handle these challenges seamlessly behind the scenes.
4. Structure and Standardize Your Output
Once you’ve secured access, the next challenge is cleaning up messy, unstructured web content into consistent, usable datasets. This involves:
- Extracting relevant fields such as name, price, date, and category
- Mapping these fields into a unified schema
- Exporting the data in machine-readable formats like JSON, CSV, or Parquet
 This step often uncovers hidden complexities.
This step often uncovers hidden complexities.
“Many teams mistakenly assume similar websites have identical data structures, but even small differences can cause errors,” says Bright Data.
Small variations in site structure, inconsistent naming, or missing fields can introduce errors that impact your AI model’s accuracy.
“The best approach is to implement automated normalization and validation to catch inconsistencies early. Treating standardization as a core engineering task ensures cleaner data and more accurate AI models.”
5. Clean, Normalize, and Validate
AI models rely on clean, predictable input data for effective training. This also avoids introducing bias or errors into its predictions.
Before feeding web data into any model, it should be:
- De-duplicated to remove repeated entries
- Cleansed of invalid characters or corrupted values
- Normalized (e.g.unifying currencies or date formats)
- Validated to flag missing or questionable fields
Many teams also apply simple validation rules, such as flagging empty mandatory fields or prices outside expected ranges, to catch issues early.
“The most important validation checks verify required fields and ensure values make sense — like prices above zero and dates in the past,” says Bright Data.
“Deduplication is key, too, since duplicates can skew models. These simple checks cut noise and protect the integrity of your training data.”
6. Automate Refresh and Change Detection
If your AI platform depends on fresh data, as most do, automating data collection and monitoring is critical. Best practices include:
- Scheduling regular data refreshes with retry logic for failures
- Monitoring source sites for layout or structural changes
- Logging and alerting on extraction issues
- Versioning data or snapshotting for historical comparison
“Automated monitoring that flags even small changes in site structure is key to avoiding pipeline failures,” Bright Data says.
“Coupled with retry logic and version control, these safeguards keep data flowing smoothly and AI training uninterrupted.”
This approach helps maintain data continuity and minimizes disruptions when source websites update or change protections.
7. Deliver Data Where It’s Needed
Finally, structured data must fit seamlessly into your AI or analytics pipelines to ensure fast, reliable model training without manual fixes or delays.
That means:
- Formatting data as expected for ingestion, whether tabular, text blocks, or labeled pairs
- Including metadata to ensure traceability
- Maintaining version control for reproducibility
“AI teams increasingly expect data delivery in formats that plug directly into their pipelines—like JSON, CSV, or Parquet — with clear metadata for traceability,” says Bright Data.
“Integration with cloud platforms and automated workflows is becoming standard to speed up training and reduce manual steps.”
Many teams integrate delivery directly with cloud platforms or model training workflows to reduce delays and manual handoffs.
Bringing It All Together
Transforming raw web data into AI-ready insights is a multi-step journey that demands careful planning, robust infrastructure, and ongoing maintenance.
From defining a focused use case to automating data refreshes and delivering clean, structured datasets, each phase plays a critical role in building reliable, effective AI systems.
Companies like Bright Data provide the tools and technology to simplify this complex process, helping teams overcome access challenges, handle data at scale, and maintain quality every step of the way.
With the right approach and infrastructure, organizations can unlock the full potential of public web data to power smarter, more responsive AI models.